
데이터베이스 백업은 예상치 못한 서버 장애를 대비하기 위해 반드시 수행해야 하는 작업 중 하나이다.
이번 포스팅에서는 데이터베이스의 대표적인 백업 방식인 '논리적 백업'과 '물리적 백업'에 대해 살펴보자
또한 MariaDB 환경에서 두 방식을 직접 구현해보고 성능을 비교해보자
1. 백업 구성도
백업을 진행하는 데 있어, 참여하는 각 주체와 그 역할을 간단한 구성도로 나타내었다.
이 때 Amazon S3는 백업 파일을 보관하기 위한 하나의 방법일 뿐, 온프레미스의 파일 스토리지를 이용해도 무방하다.

2. 백업 방식
MySQL, MariaDB에서의 백업 방식은 크게 '논리적 백업'과 '물리적 백업'으로 나뉜다.
논리적 백업은 데이터베이스의 구조와 데이터를 논리적 단위(ex. 테이블, 레코드)로 복사하는 방식이다.
즉, 데이터베이스의 DDL과 DML을 SQL 쿼리 형태로 복사하는 방식으로 동작하게 된다.
물리적 백업은 데이터베이스의 구조와 데이터를 물리적 단위(ex. 데이터 파일, 로그 파일)를 그대로 복사하는 방식이다.
즉, 데이터베이스의 실제 데이터 파일, 로그 파일, 설정 파일 등을 복사하는 방식이다.
각 방식의 세부적인 특징에 대한 비교는 다음의 표로 정리하였다.
| 논리적 백업 (Logical Backup) | 물리적 백업 (Physical Backup) | |
| 대표 도구 | mysqldump, mysqlpump | Percona XtraBackup, Mariabackup cp, tar, rsync |
| 백업 방식 | MySQL DDL, DML을 SQL 쿼리 형태로 추출 | MySQL의 데이터 파일, 로그 파일을 직접 복사 |
| 백업 데이터 | 작음 (.sql) |
큼 (.ibd / .frm / .myd / .ib_logfile) |
| 백업 속도 | 느림 | 빠름 |
| 복구 속도 | 느림 (SQL 문을 실행해야 함) |
빠름 (파일을 복사하면 바로 사용 가능) |
| 복구 유연성 | 데이터베이스, 테이블 단위 복구 | 데이터베이스 단위 복구 |
| 백업 중 잠금(Lock) 발생 |
잠금 없음 (InnoDB에서 --single-transaction 옵션 사용 시) |
잠금 없음 |
| 증분/차등 백업 지원 | 지원하지 않음 | 지원함 |
| 플랫폼 호환성 |
높음 (다른 MySQL 버전이나 플랫폼에서 사용 가능) |
낮음 (MySQL 버전과 환경이 동일해야 복구 가능) |
| 사용 사례 | 소규모 데이터베이스, 특정 테이블 백업이 필요한 경우 | 대규모 데이터베이스, 빠른 백업/복원이 필요한 경우 |
3. 논리적 백업 과정
1) 소스 서버 데이터 백업하기
# 백업 파일 생성
mysqldump -uroot -p --single-transaction \
--opt --routines --triggers --events --hex-blob \
--all-databases > source_data.sql# 백업 압축 파일 생성
# gzip 압축 (단일 쓰레드)
mysqldump -uroot -p --single-transaction
--opt --routines --triggers --events --hex-blob
--all-databases | gzip > source_data.sql.gz
# pigz 압축 (멀티 쓰레드)
mysqldump -uroot -p --single-transaction
--opt --routines --triggers --events --hex-blob
--all-databases | pigz -p 8 > source_data.sql.gz명령어 분석
- mysqldump
- MySQL 데이터베이스 백업 도구이다.
- 데이터베이스의 테이블 구조와 데이터를 SQL 파일로 덤프(dump)한다.
- -uroot
- 데이터베이스에 접속할 사용자 이름(user)을 지정한다.
- -u는 "user"의 약자로, 뒤에 사용자 이름이 붙는다.
- 여기서는 root 사용자다.
- -p
- 비밀번호를 입력하라는 옵션입니다. 이 플래그만 사용하면 실행 시 비밀번호를 입력하라는 프롬프트가 나타난다.
- 실행 후 "Enter password:" 메시지가 표시되며, 사용자가 직접 입력해야 한다.
- cf. 보안을 위해 명령어에 직접 비밀번호를 쓰는 대신 (-p비밀번호), 프롬프트로 입력하는 방식이 권장된다.
- --single-transaction
- InnoDB 테이블들에 대해 하나의 트랜잭션을 사용하여 일관된 스냅샷을 생성한다.
- 테이블이나 레코드에 잠금을 걸지 않고, 서비스 중단 없이 백업이 가능하다.
- MyISAM 테이블에는 적용되지 않는다.
- --master-data=2
- 바이너리 로그 파일명과 위치 정보를 포함하는 구문이 백업 파일 헤더에 기록될 수 있게 하는 옵션이다.
- 복제(replication) 설정에서 사용되며, 백업 후 복구 시 복제 동기화 시점을 지정할 수 있다.
- =1은 주석 없이 실행 가능한 명령어로 추가한다. (→ 'CHANGE MASTER TO' )
- =2는 명령어를 주석으로 추가한다는 뜻이다.
- --opt
- 여러 최적화 옵션을 한 번에 활성화하는 단축 옵션이다.
- 포함 옵션
- --add-drop-table: 테이블을 덮어쓰기 전에 DROP TABLE IF EXISTS 명령 추가
- --add-locks: LOCK TABLES 및 UNLOCK TABLES 포함 (백업 속도 향상)
- --create-options: 테이블 생성 시 CREATE TABLE 옵션을 유지
- --disable-keys: 인덱스 비활성화 후 데이터 삽입 후 재활성화 (Insert 속도 최적화)
- --extended-insert: 여러 행을 하나의 INSERT 문으로 묶어 사용
- --lock-tables: 백업 중 테이블 잠금
- --quick: 백업 시 SELECT * FROM table이 아닌, mysql_use_result()를 사용하여 한 줄씩 가져옴 (메모리 최적화)
- --set-charset: 문자열 인코딩 보장
- cf. --single-transaction이 사용되면 --lock-tables는 무시된다.
- --routines
- 저장 프로시저(stored procedures)와 함수(functions)를 백업에 포함한다.
- --triggers
- 트리거(triggers)를 백업에 포함한다.
- --hex-blob
- BLOB, BINARY, VARBINARY 등 이진 데이터를 16진수(hexadecimal) 형식으로 변환하여 덤프한다.
- 복원 시, 이진 데이터가 손상되거나 인코딩 문제로 인해 깨지는 것을 방지한다.
- --all-databases
- 서버에 있는 모든 데이터베이스를 백업한다.
- 특정 데이터베이스를 지정하지 않고 전체를 대상으로 한다.
- | pv
- 'Pipe Viewere'의 약자로, 파이프를 통해 작업 진행 상황을 시각적으로 표시해주는 옵션이다.
- | gzip
- 단일 파일을 GZIP 형식으로 압축한다.
- > source_data.sql
- mysqldump의 결과를 source_data.sql 파일로 저장한다.
- >는 리디렉션 연산자로 터미널에 출력되는 백업 데이터를 파일로 저장하는 역할을 한다.
2) AWS S3 업로드하기
- aws 연결 과정은 생략한다.
- 백업 파일을 S3에서 관리하기 위해, S3 서버로 전송한다.
aws s3 cp source_data.sql s3://my-backup-bucket/
3) 복구 서버에서 S3에 저장된 백업 파일 다운로드하기
aws s3 cp s3://my-backup-bucket/source_data.sql ./
4) 백업 파일 복원하기
- 복구 서버에서 먼저 target_database를 생성한다.
- 압축된 파일을 풀고 source_data_sql에 있는 SQL 명령어들을 target_database에 복원한다.
mysql -uroot -p target_database < source_data.sql
📖 전체 스크립트
- 위에서 설명한 물리적 백업 과정에서 mysqldump와 S3 업로드가 정상적으로 실행되었는지,
그리고 실행 시간은 어떻게 되는지 추적하기 위해 로그 출력을 추가한 전체 스크립트는 다음과 같다.
[mysqldump-full-backup-compress.sh]
#!/bin/bash
# DB 설정
USER="{MariaDB 서버 사용자}"
PASSWORD="{MariaDB 서버 비밀번호}"
DATABASE="{MariaDB 데이터베이스, 특정 데이터베이스 백업 시}"
# 백업 파일
date=$(date +%Y%m%d)
file_name="${date}-full_mysqldump.sql.gz"
backup_path="/backup/${DATABASE}/compress"
backup_file_path="$backup_path/$file_name"
# AWS S3 설정
bucket_name="{S3 버킷 이름}"
bucket_folder="$DATABASE/full_backup"
s3_path="s3://$bucket_name/$bucket_folder/$file_name"
# 로그 설정
log_path="/backup/${DATABASE}/log"
log_file_path="$log_path/mysqldump.log"
run_log_path="$log_path/run.log"
# 로그 출력 함수
log() {
echo "$1" >> "$log_file_path"
}
# 시간 포맷 함수
time_format() {
local total_seconds=$1
local hours=$((total_seconds / 3600))
local minutes=$(((total_seconds % 3600) / 60))
local seconds=$((total_seconds % 60))
log "=== 총 실행 시간: ${hours}시간 ${minutes}분 ${seconds}초 ==="
}
# 백업 실행
backup_database() {
log " "
log "[$(date +%Y%m%d_%H%M%S)] $DATABASE 백업 실행"
mysqldump -u"$USER" -p"$PASSWORD" \
--single-transaction \
--opt --routines --triggers --events --hex-blob \
"$DATABASE" | pigz -p 8 > "$backup_file_path" \
2> "$run_log_path"
# 백업 성공 여부 확인
if [ $? -eq 0 ]; then
log "[$(date +%Y%m%d_%H%M%S)] 백업 완료: $backup_file_path"
else
log "[$(date +%Y%m%d_%H%M%S)] 백업 실패"
exit 1
fi
}
# AWS S3 파일 전송
upload_s3() {
log " "
log "[$(date +%Y%m%d_%H%M%S)] S3 업로드 "
aws s3 cp "$backup_file_path" "$s3_path"
if [ $? -eq 0 ]; then
log "[$(date +%Y%m%d_%H%M%S)] S3 업로드 성공: $s3_path"
else
log "[$(date +%Y%m%d_%H%M%S)] S3 업로드 실패"
exit 2
fi
}
# 메인 실행
main() {
log " "
start_time=$(date +%s)
mkdir -p "$log_path"
mkdir -p "$backup_path"
backup_database
upload_s3
end_time=$(date +%s)
duration=$(time_format $((end_time - start_time)))
log " "
}
main
4. 물리적 백업 과정
1) Mariabackup 설치하기
- MariaDB 10.3 이상의 버전에서 Percona XtraBackup이 지원되지 않는다.
- MariaDB와 Mariabackup은 동일한 버전을 사용해야 한다.
- https://mariadb.com/kb/en/percona-xtrabackup-overview/#compatibility-with-mariadb
- Mariabackup 설치 여부를 파악하고, 설치되지 않았다면 별도로 설치를 해야 한다.
mariabackup --version
# Ubuntu/Debian
sudo apt-get update
sudo apt-get install mariadb-backup
# CentOS
sudo yum install mariadb-backup
Error. "No package MariaDB-backup available."
mariadb-backup 패키지를 설치 시, MariaDB 공식 레포지토리(/etc/yum.repos.d/MariaDB.repo)에서 패키지를 찾아 다운로드 합니다. 하지만 yum install mariadb 와 같이 CentOS 기본 레포지토리에서 설치한 경우, MariaDB 공식 레포지토리가 존재하지 않을 수 있습니다. 따라서 위 명령어가 실패할 수 있는데, 이럴 경우 공식 레포지토리를 등록해야 합니다.
아래 명령어를 통해서 MariaDB 버전에 맞는 MariaDB.repo를 설치할 수 있습니다.
sudo curl -LsS https://downloads.mariadb.com/MariaDB/mariadb_repo_setup | sudo bash -s -- --mariadb-server-version=$VERSION
추가로 아래의 공식 문서에서 스크립트 추가 옵션, Minor 버전에서는 어떻게 설정할 수 있을지와 같은 자세한 정보를 확인할 수 있습니다.
- https://mariadb.com/kb/en/mariadb-package-repository-setup-and-usage/
- https://mariadb.com/kb/en/yum/
- https://archive.mariadb.org/
2-1) 전체 백업하기 (Full Backup)
- 백업을 저장할 디렉터리는 비어 있어야 하고, 존재하지 않는 경우 자동으로 생성된다.
- Mariabackup의 "--compress" 옵션은 deprecated 되어, 더 이상의 사용이 권장되지 않는다.
- 대신 백업을 stream(stdout)으로 출력한 뒤, "gzip, pigz, 7zip"과 같은 외부 압축 도구를 사용하는 방법을 권장한다.
# 디렉토리 백업 (압축 X)
mariadbbackup --backup \
--target-dir=${백업 파일을 저장할 디렉토리} \
--user=${사용자} --password=${비밀번호}
# 디렉토리 백업 + pigz 압축
mariabackup --backup \
--target-dir=${백업 파일을 저장할 디렉토리} \
--user="$USER" --password="$PASSWORD" \
--parallel=8 \
tar -I 'pigz -p 8' -cf "$backup_file_path.tar.gz" "$backup_file_path"
# 스트림 백업 + pigz 압축
mariabackup --backup --stream=xbstream \
--user="$USER" --password="$PASSWORD" \
--parallel=8 \
| pigz -p 8 > "$backup_file_path"
3) AWS S3 업로드하기
- aws 연결하는 과정 생략
- 백업 파일을 S3에서 관리하기 위해, S3 서버로 전송한다.
aws s3 cp backupstream.gz s3://my-backup-bucket/
4) 복구 서버에서 S3에 저장된 백업 파일 다운로드하기
# aws s3 cp s3://버킷이름/파일경로 로컬경로
aws s3 cp s3://my-backup-bucket/backupstream.gz ./
5) 백업 파일 검증하기
- 압축 파일을 풀고, 해당 백업 파일이 유효한지 검증한다.
- 백업 중 진행 중이던 트랜잭션은 redo log에 기록되어, 백업 시점에서 이 트랜잭션이 반영되지 않은 상태가 될 수 있다.
- --prepare : redo log를 분석해 백업 시점까지의 모든 트랜잭션을 백업 파일에 적용하여 일관성(point-in-time) 확보
gunzip backup_file.gz.gz # 단일 쓰레드
pigz -d backup_file.gz.gz # 멀티 쓰레드
mariadb-backup --prepare \
--target-dir=${백업 파일 경로}
6) 백업 파일 복원하기
- 검증 후에는 --copy-back 또는 --move-back 옵션을 사용하여 복원할 수 있다.
- --copy-back: 백업 파일 복사
- --move-back: 백업 파일 이동
- 둘 다 실행 전에 MariaDB 서버가 완전히 종료시켜야 한다.
- 위 명령어를 그대로 사용할 시, 백업된 데이터가 MariaDB 인스턴스의 데이터 디렉토리(일반적으로 /var/lib/mysql)를 그대로 덮어씌우는 방식으로 동작합니다. 따라서 기존의 DB 서버가 그대로 날라갈 수 있으니, 반드시 복사해두도록 합시다..
# 기존 MariaDB 데이터 디렉토리 복사
cp -r /var/lib/mysql ./original_mysql_backup# DB 중지
systemctl stop mariadb
# DB 삭제
rm -rf /var/lib/mysql/*
# 백업 데이터 복사
mariadb-backup --copy-back \
--target-dir=/var/mariadb/backup/
# 파일 권한 수정 (mysql 사용자에게 데이터 디렉토리 소유권 설정)
chown -R mysql:mysql /var/lib/mysql/
# DB 재시작
systemctl start mariadb
- 전체 MariaDB 서버가 아닌 특정 데이터베이스만 복원하는 상황
- 백업 파일 생성 시, --databases 옵션 사용
# 기존 데이터 디렉토리(/var/lib/mysql)를 건드리지 않고, 복구할 임시 데이터 디렉토리를 생성하고 지정해준다.
mariadb-backup --copy-back --target-dir=${백업 파일 경로} --datadir=${복구할 임시 디렉토리 경로}
# MariaDB 서버 중지
systemctl stop mariadb
# 복구된 my_database 디렉토리를 기존 MariaDB 데이터 디렉토리로 수동 복사
cp -r /tmp/restore/mydb /var/lib/mysql/
# 디렉토리 권한 수정
chown -R mysql:mysql /var/lib/mysql/my_database
# MaraDB 서버 재시작
systemctl start mariadb
7) 다른 도구를 사용한 복원
- 전체 백업이 준비되면, cp나 rsync와 같은 파일 복사 도구를 사용하여 바로 백업 파일을 복원할 수 있다.
- 복구 서버의 MariaDB 서버 프로세스가 중지되어야 한다.
rsync -avrP /var/mariadb/backup /var/lib/mysql/
chown -R mysql:mysql /var/lib/mysql/
[mariabackup-full-backup-compress.sh]
#!/bin/bash
# DB 설정
USER="{MariaDB 사용자}"
PASSWORD="{MariaDB 비밀번호}"
DATABASE="{MariaDB 데이터베이스, 특정 데이터베이스 백업 시 지정}"
# 백업 파일
date=$(date +%Y%m%d)
file_name="${date}-full.gz"
backup_path="/home/db_dump/${DATABASE}/compress"
backup_file_path="$backup_path/$file_name"
# AWS S3 설정
bucket_name="{S3 버킷 이름}"
bucket_folder="$DATABASE/full_backup"
s3_path="s3://$bucket_name/$bucket_folder/$file_name"
# 로그 설정
log_path="/home/db_dump/${DATABASE}/log"
log_file_path="$log_path/mariadb-fullbackup.log"
run_log_path="$log_path/run.log"
# 로그 출력 함수
log() {
echo "$1" >> "$log_file_path"
}
# 시간 포맷 함수
time_format() {
local total_seconds=$1
local hours=$((total_seconds / 3600))
local minutes=$(((total_seconds % 3600) / 60))
local seconds=$((total_seconds % 60))
log "=== 총 실행 시간: ${hours}시간 ${minutes}분 ${seconds}초 ==="
}
# 백업 실행
backup_database() {
log " "
log "[$(date +%Y%m%d_%H%M%S)] $DATABASE 백업 실행"
mariabackup --backup --stream=xbstream \
--user="$USER" --password="$PASSWORD" \
--databases="$DATABASE" \
--parallel=4 \
| pigz -p 8 > "$backup_file_path" \
2> "$run_log_path"
# 백업 성공 여부 확인
if [ $? -eq 0 ]; then
log "[$(date +%Y%m%d_%H%M%S)] $DATABASE 백업 완료: $backup_file_path"
else
log "[$(date +%Y%m%d_%H%M%S)] $DATABASE 백업 실패"
exit 1
fi
}
# AWS S3 파일 전송
upload_s3() {
log " "
log "[$(date +%Y%m%d_%H%M%S)] S3 업로드 "
aws s3 cp "$backup_file_path" "$s3_path"
if [ $? -eq 0 ]; then
log "[$(date +%Y%m%d_%H%M%S)] S3 업로드 성공: $s3_path"
else
log "[$(date +%Y%m%d_%H%M%S)] S3 업로드 실패"
exit 2
fi
}
# 메인 실행
main() {
log " "
start_time=$(date +%s)
mkdir -p "$log_path"
mkdir -p "$backup_path"
backup_database
upload_s3
end_time=$(date +%s)
duration=$(time_format $((end_time - start_time)))
log " "
}
main
2-2) 증분 백업하기 (Incremental Backup)
- 증분 백업을 수행하기 전에 먼저 전체 백업을 해야 한다.
- 전체 백업 이후, 증분 백업을 할 수 있다.
- 증분 백업을 저장할 디렉터리는 비어 있어야 하고, 존재하지 않는 경우 자동으로 생성된다.
- 전체 백업 파일은 압축 상태가 아닌, 디렉토리 상태여야 한다.
- 압축 상태일 경우 xtrabackup_checkpoints, xtrabackup_info 를 참조할 수 없어, 증분 백업을 할 수 없다.
mariabackup --backup \
--target-dir=${전체백업 파일을 저장할 디렉토리} \
--user="$USER" --password="$PASSWORD" \
--parallel=8 \
mariabackup --백업 \
--target-dir=${증분백업 파일을 저장할 디렉토리} \
--incremental-basedir=${LSN 참조 경로(=전체백업 파일을 저장한 디렉토리)} \
--user=${사용자} --password=${비밀번호}
5-2) 증분 백업 검증하기
- 증분 백업을 검증하기 앞서, 먼저 풀 백업 검증을 해야 한다.
- 전체 백업 검증 이후, 증분 백업을 풀 백업에 merge하여 복원이 가능한 상태로 만든다.
즉, 풀 백업 디렉토리(--target-dir)가 증분 백업 시점까지의 데이터를 반영하도록 업데이트 한다.
- 전체 백업 검증 이후, 증분 백업을 풀 백업에 merge하여 복원이 가능한 상태로 만든다.
mariabackup --prepare \
--target-dir=${전체백업 파일을 저장한 디렉토리} \
--incremental-dir=${증분백업 파일을 저장한 디렉토리}
📖 전체 스크립트
- 위에서 설명한 논리적 백업 과정에서 mariabackup과 S3 업로드가 정상적으로 실행되었는지,
그리고 실행 시간은 어떻게 되는지 추적하기 위해 로그 출력을 추가한 전체 스크립트는 다음과 같다.
5. 성능 비교
1) 첫 번째 테스트 (논리적 백업, 물리적 백업)
| 논리적 백업(mysqldump) | 물리적 백업(mariabackup) | |
| 백업 DB 크기 | 5GB | 5GB |
| 백업 압축 파일 크기 | 500MB | 3GB |
| 백업 소요 시간 | 1분 40초 | 8분 |
# mysqldump 백업
mysqldump -u"$USER" -p"$PASSWORD" \
--single-transaction \
--opt --routines --triggers --events \
| gzip > "$backup_file_path"
# mariabackup 백업
mariabackup --backup \
--user="$USER" --password="$PASSWORD" \
--stream=xbstream \
| gzip > "$backup_file_path"
백업 데이터베이스 5GB 크기로 진행했다.
당연히 mariabackup이 속도 면에서 빠를 것이라 생각했지만, 결과는 스토리지 / 속도 측면 모두 mysqldump 가 더 뛰어났다.
참고로 네트워크 전송 시간은 파일 크기에 비례하게 된다.
따라서 S3 전송 소요 시간 역시, mysqldump가 훨씬 빨리 전송되게 된다.
2) 두 번째 테스트 (백업 디렉토리 압축)
| 논리적 백업(mysqldump) | 물리적 백업(mariabackup) | |
| 백업 DB 크기 | 5GB | 5GB |
| 백업 압축 전 파일 크기 | 8GB | 13GB |
| 백업 압축 후 파일 크기 | 500MB | 3GB |
| 백업 소요 시간 | 1분 40초 | 1분 30초 |
| 백업 파일 압축 시간 | 6분 30초 |
mariabackup --backup \
--user="$USER" --password="$PASSWORD" \
--target-dir="$backup_file_path" \
tar -czf "$backup_file_path.tar.gz" "$backup_file_path""mariabackup이 왜 이렇게 느리게 동작할까?" 라는 물음에, 백업 압축 파일 생성 과정을 분리하여 그 시간을 측정해보았다.
👉 백업 압축 파일 생성 = 백업 파일 생성 + 백업 디렉토리 tar gzip 압축
그 결과 백업 파일을 생성하는 데 걸리는 프로세스보다, 백업 파일을 압축하는 데 걸리는 시간이 더 오래 걸렸음을 알 수 있었다.
cf. 백업 디렉토리 또한 파일로 지칭하여 표현하였습니다.
3) 세 번째 테스트 (백업 디렉토리 압축, 멀티 쓰레드)
| 물리적 백업(gzip) | 물리적 백업(pigz -p 4) | 물리적 백업(pigz -p 8) | |
| 백업 DB 크기 | 5GB | 5GB | 5GB |
| 백업 소요 시간 | 8분 | 3분 30초 | 2분 30초 |
mariabackup --backup --stream=xbstream \
--user="$USER" --password="$PASSWORD" \
| pigz -p 8 > "$backup_file_path"두 번째 테스트에서 mariabackup의 병목 지점이 압축 과정이라는 것을 깨달았다..!
기존의 압축 프로세스는 단일 스레드로 동작하는 gzip을 사용했다.
이번 변경점은 멀티 스레드로 동작하는 pigz을 사용하여 더 빠르게 압축을 할 수 있도록 했다.
기본적으로 pigz는 서버의 CPU 코어 수만큼의 쓰레드를 사용해서 압축을 한다. 하지만 모든 코어의 쓰레드를 사용하게 되면, 컨텍스트 스위칭이 일어나 서버 전체의 성능이 저하될 수 있어 테스트 후 옵션을 조절하는 과정을 거쳤다.
4) 네 번째 테스트 (mariabackup 멀티 쓰레드)
| 물리적 백업(--parallel=4, pigz -p 8) | 물리적 백업(--parallel=8, pigz -p 8) | |
| 백업 DB 크기 | 5GB | 5GB |
| 백업 소요 시간 | 2분 20초 | 2분 |
mariabackup --backup --stream=xbstream \
--user="$USER" --password="$PASSWORD" \
--parallel=4 \
| pigz -p 8 > "$backup_file_path"현재 백업 프로세스는 mariabackup이 생성하는 스트림을 pigz를 통해 실시간으로 압축하는 구조로 구성되어 있다. 압축 속도는 충분히 개선하였고, CPU 모니터링(htop, top -n 1 | grep "Cpu") 결과, 백업 과정에서도 CPU 사용률은 높지 않음을 확인할 수 있었다.
mariabackup 자체도 --parallel 옵션을 통해 병렬 처리가 가능하므로, 해당 옵션을 조정하면서 추가적으로 최적화가 가능한지 테스트를 진행했다.
Q. 증분 백업, 정말 효율적일까?
mysqldump와 mariabackup을 활용해 풀 백업을 구현하고 테스트해 본 후, 증분 백업을 통해 스토리지를 더 효율적으로 관리할 수 있지 않을까? 하는 고민이 들었다
우선 증분 백업이란 마지막 백업 이후의 변경된 데이터만 백업하는 방식이다.
이처럼 변경된 내용만 백업이 되므로, 백업 파일의 용량을 줄이고 백업 시간도 단축할 수 있다는 점에서 효율적이다.
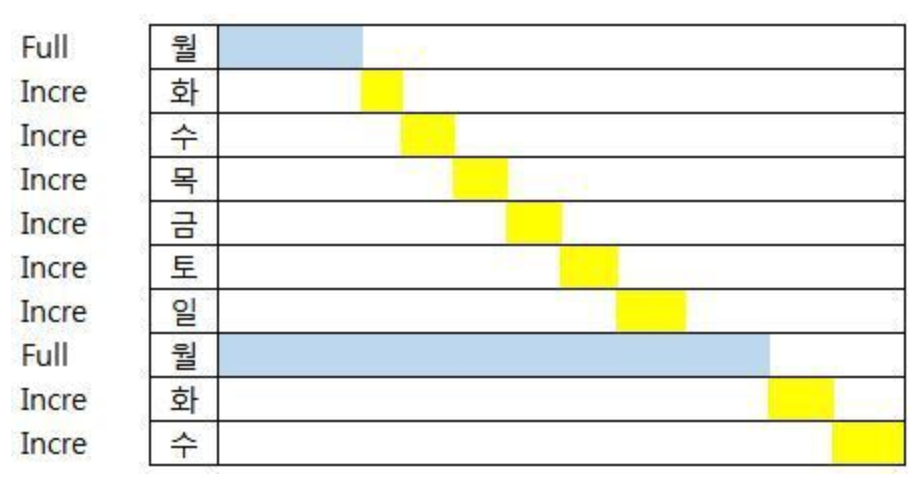
💭 개념은 효율적인데 구현은?
개념적으로는 증분 백업이 확실히 효율적이다. 하지만 실제 구현 측면에서는 생각해 볼 부분이 있다.
우선 mysqldump 에서는 증분 백업을 지원하지 않는다.
대안으로 풀 백업 + 바이너리 로그로 증분 백업처럼 구현할 수는 있지만, 복원 시에 풀 백업을 먼저 적용한 후 해당 시점 이후의 바이너리 로그를 적용하기 때문에, 일반적인 백업 파일 관리와는 차이가 있다.
그러면 mariabackup에서의 증분 백업은 어떨까?
mariabackup은 증분 백업을 공식적으로 지원을 하지만 주의할 점이 있다.
먼저 백업 파일의 LSN을 추적하기 위해, 풀 백업과 증분 백업한 모두 파일이 아닌 디렉토리 형태로 생성되어야 한다.
즉, 압축된 파일 형태로 존재해서는 안된다.
물론 --extra-lsndir 옵션을 사용해서 LSN 정보를 별도의 디렉토리에 저장할 수 있다.
하지만 압축된 백업을 다시 풀어야만 증분 백업을 병합할 수 있다.
문제는 압축/압축 해제 과정에서 서버 리소스가 불필요하게 소모하게 된다는 점이다.
또한, mariabackup으로 생성된 디렉토리 형태의 백업 데이터는 압축하지 않으면 원본 DB보다 더 많은 스토리지를 차지하게 된다.
이 때문에 서버 내에서의 스토리지 관리가 매우 비효율적이게 된다.
반대로 서버 스토리지 여유가 충분하고, 백업 속도를 더 중요하게 생각한다면, 압축하지 않는 디렉토리 형태의 증분 백업 방식이 더 적합할 수 있다.
✅ 결론
스토리지 효율성이 중요하다면, 압축된 풀 백업 방식이 더 현실적인 선택이 될 수 있다.
백업 속도가 중요하다면, 디렉토리 형태의 증분 백업 방식도 고려해볼 만한 선택이 될 것 같다.
참고 문서
- MariaDB 공식문서
https://mariadb.com/kb/en/percona-xtrabackup-overview/
https://mariadb.com/kb/en/full-backup-and-restore-with-mariabackup/
- 장애와 관련된 XtraBackup 적용기
https://techblog.woowahan.com/2576/
- mariabackup 풀 백업, 증분 백업
https://dksek3050.tistory.com/92
- Docker 내의 Mariabackup
'DB' 카테고리의 다른 글
| [DB] 게시글 - 파일 테이블 설계 (0) | 2024.12.22 |
|---|---|
| [MySQL] View Processing Alogrighms (MERGE vs. TEMPTABLE) (3) | 2024.10.11 |
| [MySQL] Partition 3. DATE 기반 월별 파티션 구현 (0) | 2024.08.05 |
| [MySQL] Partition 2. 적용하기 전 개념 정리 (0) | 2024.08.02 |
| [MySQL] Partition 1. 테이블 수동 분할과 파티셔닝 (+. 샤딩 / 래플리케이션) (0) | 2024.07.30 |